This is an excerpt from the "future outlook" section of my thesis titled "Reproducible Data Analysis in Drug Discovery with Scientific Workflows and the Semantic Web" (click for the open access full text), which aims to provide various putative ways towards improved reproducibility, understandability and verifiability of computer-aided research.
Historically, something of a divide has developed between the metadata rich datasets and approaches in the world of Semantic Web/Ontologies/Linked Data, versus in the Big Data field in particular, which has been at least initially mostly focused on large unstructured datasets.
Even today’s focus on data science and development of predictive models using technologies like deep learning, is to a large extent focusing on data sets with a relatively non-complex structure (2D-images), and not so much on merging knowledge stored in opaque deep learning models with explicit knowledge stored in ontologies and knowledge bases of different kinds.
In order to ripe the fruits of the recent boom in developments of machine learning technologies also in other fields with much more complex and rich data but without large numbers of very similar examples, it seems we will need to link Big Data science with smart data science. That is, state-of-the-art methods and tools from data science, Big Data and machine learning, with semantic data modelling, such as with technologies in Semantic Web, Linked Data and Logic Programming.
Personally, I think it is particularly the reasoning capabilities around linked/semantic data, that need further development. Based on very positive experience of using SWI-Prolog to implement lookup methods in cheminformatics, I am personally a strong believer in using logic programming approaches as a very practical approach to implement extremely intelligent reasoning systems that can still be easy to understand.
At the Linked Data Sweden symposium in Uppsala in April 2018, I presented these ideas and suggested that SWI-Prolog in particular might be a suitable integration platform for what we could call linked data science, or linked big data science (slides and video for the presentation here).
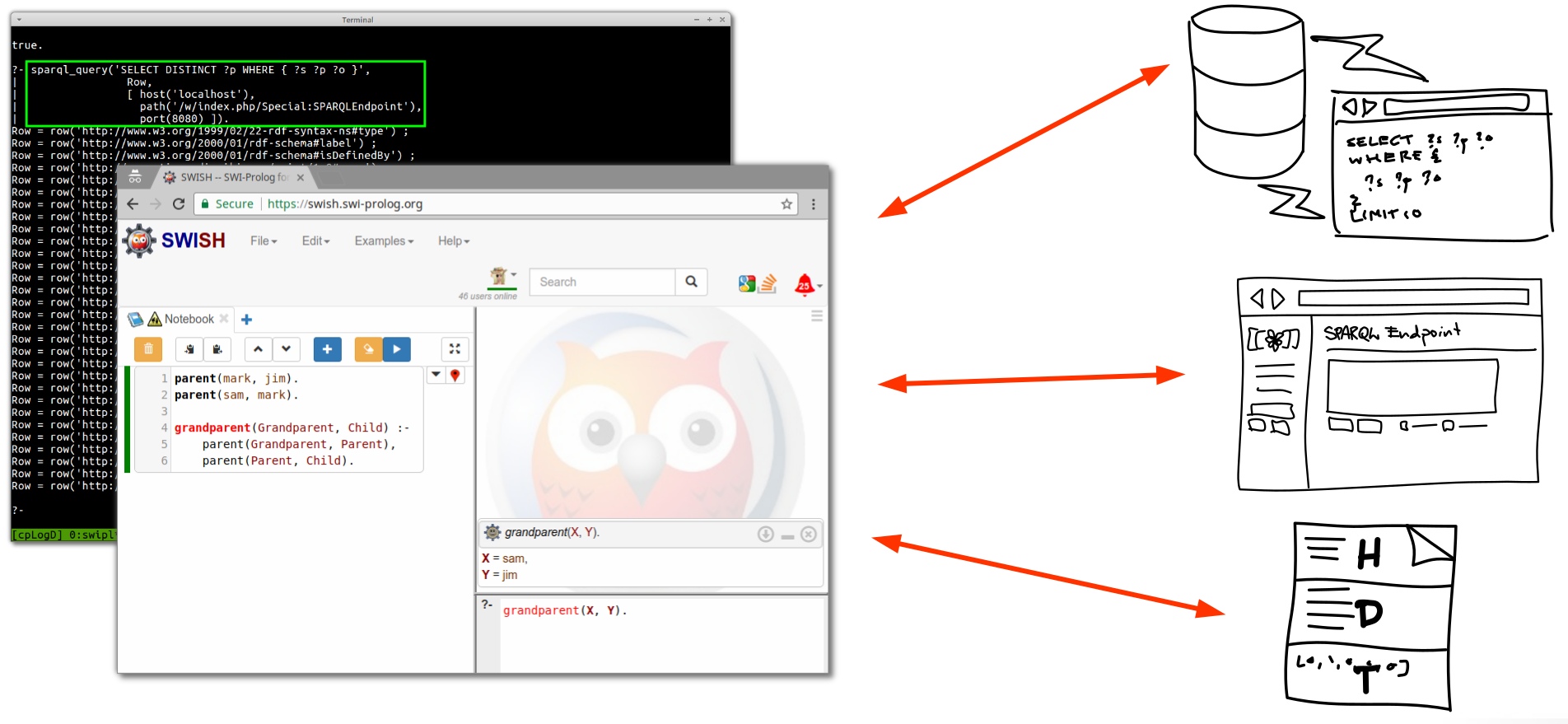
SWI-Prolog is a mature, well-maintained and high quality open source Prolog implementation, with an extensive set of libraries, including top-class support for interacting with RDF datasets and SPARQL endpoints. The main drawback of SWI-Prolog for large datasets has been that it has lacked a generic disk based storage solution. Instead, full datasets have had to be loaded into memory before doing complex queries upon them. A recently developed plugin for the RDF-HDT format seems to provide an interesting way to solve this problem, at least for read-only access to large datasets. Since RDF-HDT is an indexed format, it allows doing queries against its data by only loading the index into memory, not the full dataset. Since SWI-Prolog also can fluently incorporate SPARQL queries into logic programming queries, this also provides an ability to interact with many large-scale datasets such as Wikidata, not to mention Semantic MediaWikis with the RDFIO extension that we developed in paper III. In the release notes for RDFIO version 3.0.1 and 3.0.2 we provided screenshots demonstrating the ability to query Semantic MediaWiki data via the SPARQL endpoint provided with RDFIO, from SWI-Prolog. SWI-Prolog also provides a web based notebook quite similar to Jupyter notebooks called SWISH, allowing to use the notebook paradigm for interactive data exploration.
The described vision is illustrated in the figure above, which illustrates how SWI-Prolog can be used as an interactive integration workbench for accessing and fluently integrating knowledge from external linked datasets. Data sources that can be accessed include SPARQL endpoints (e.g. RDFIO powered Semantic MediaWikis) or RDF-HDT data files. These can be fluently integrated into the logic programming environment, via rules or queries, which can be used as building blocks for further rules or queries. While the SWISH screenshot is here used only for illustration purposes and shows toy example code, the terminal screenshot in the background is a real-world one, showing how SWI-Prolog is interacting with an external SPARQL endpoint of an RDFIO-powered Semantic MediaWiki.